
The Spiral Widens: Why Every Profession Now Has the Vibe-Coding Problem
And What to Do About It (Essay 2 in Spiral Series)

I. The Illustration Was Software. The Problem Is Universal.
Imagine that a Supreme Court decision has just changed how courts interpret a standard testamentary capacity clause — the language in a will that establishes whether the testator understood what they were signing. The decision narrows the standard of evidence required to challenge a will on capacity grounds. Millions of existing wills may now be more vulnerable to contest than their authors believed.
How does that information reach the people who need it? Through law review articles, bar association notices, continuing legal education (CLE) seminars, and word of mouth across the profession. It is a slow, uneven, lossy process, but it exists. A lawyer who drafted that will has professional obligations, relationships, and channels through which the news will eventually arrive. The legal profession’s mechanisms for propagating a ruling are imperfect, but they are real.
Now consider the person who asked an LLM to draft their will last year. They used one of the general-purpose AI assistants — a perfectly reasonable thing to do, and the resulting document looked entirely professional. Call it vibe-writing1 — the document-drafting equivalent of vibe-coding: natural language in, plausible artifact out, no verified constraints in between. That person has no professional obligation to stay current on estate law. No bar association will notify them. No CLE requirement will surface the ruling. The will still looks correct. It may not be.
There is a subtler problem underneath that one. Even if the LLM that drafted the will had encountered the SCOTUS ruling — even if it exists somewhere in the model’s training data — the model would still tend to generate the old clause language, because the training distribution is overwhelmingly weighted toward the old boilerplate. Hundreds of thousands of prior documents use the superseded language; a handful use the new. Frequency beats recency in a probabilistic system. The model does not retrieve the current standard; it reconstructs the most statistically probable output from everything it has ever seen.
This is an architecture gap, not a knowledge gap. Injecting the ruling at query time through retrieval-augmented generation helps but does not solve it: the probability mass of the prior distribution still dominates generation. The only fix is to bypass generation entirely for verifiable components: to retrieve the current clause rather than reconstruct a probabilistic approximation of it.
Sophisticated law firms already understand this, at least implicitly. A substantial commercial ecosystem of clause library tools has grown up to address exactly this problem within professional practice: ClauseBase, Henchman/Lexis Create+, Draftwise, Spellbook, and others.2 These tools allow firms to build, version, and track verified clause libraries; to surface pre-approved language at drafting time; to benchmark clauses against market-standard terms. The private library layer the spec library describes is already commercially well-developed. The gap is not in the tools; it is in what the tools do not do: they are firm-centric and backward-looking. When the SCOTUS decision changes the meaning of a clause, none of them automatically notify every firm and every individual who has deployed that clause. That alert mechanism is missing.
The contrast is striking. A law firm using ClauseBase has curated, versioned, tracked clause libraries and some process (however informal) for learning about legal developments and updating its library. The individual who asked an LLM to draft their will has none of these protections, no professional update channel, and no awareness that anything has changed.
These are solvable problems. But before proposing a solution, it is worth stating what kind of solution is being sought: what counts as a real answer rather than a speculative one. In 1976, Russell Ackoff, designing an idealized system for scientific communication, proposed two constraints that any viable redesign must satisfy: it may use only technology known to be feasible today, and it must be operationally viable — capable of functioning if it were actually built. In his words, such a design is “not a work of science fiction; it is a feasible, however improbable, design.”3 Both constraints apply here.
Now imagine that testamentary capacity clause language were standardized and versioned — a verified entry in a shared library, accessible to LLMs, identified by a stable version number, with a record of which documents deployed it. The decision arrives. The spec maintainer annotates the entry: clause v4.2, interpretation changed by Smith v. Jones, decided [date], challenge threshold narrowed in these specific circumstances. Every practitioner and individual registered as a user of clause v4.2 receives an alert. The review is triggered automatically, not eventually. And when the next LLM generates a testamentary capacity clause, it retrieves the current version — not a probabilistic reconstruction of the old one.
This is not a fantasy. It is the direct consequence of taking the spec library seriously. And it is not only about legal documents.
Figures 1a and 1b show why this matters in practice.
Figure 1a shows the process of LLM artifact generation with which we’ve all recently become familiar. The LLM is trained on a massive corpus of information — of good, bad, and indifferent quality and accuracy. The artifacts it produces are WAGs (“Wild Ass Guesses”): probabilistic reconstructions with no verified grounding, assembled from whatever patterns the training distribution happens to contain.

Figure 1a. Current LLM Generation. WAG (“Wild Ass Guess”): probabilistic reconstruction with no verified grounding, tagged for human review.
Figure 1b shows the proposed architecture. Here the LLM draws on two distinct sources: the broad training data common to current systems, and a spec library — a structured collection of verified, versioned components retrieved at generation time rather than baked into the model’s weights. The output artifact is then a combination of three kinds of material: the user’s specific inputs, retrieved verified components, and WAGs where no verified component exists. Critically, the LLM reports the source of each kind of material to the user — ideally in the body of the artifact itself, as comments in generated code, as margin annotations in a generated contract, or as explicit provenance metadata in any other kind of document.
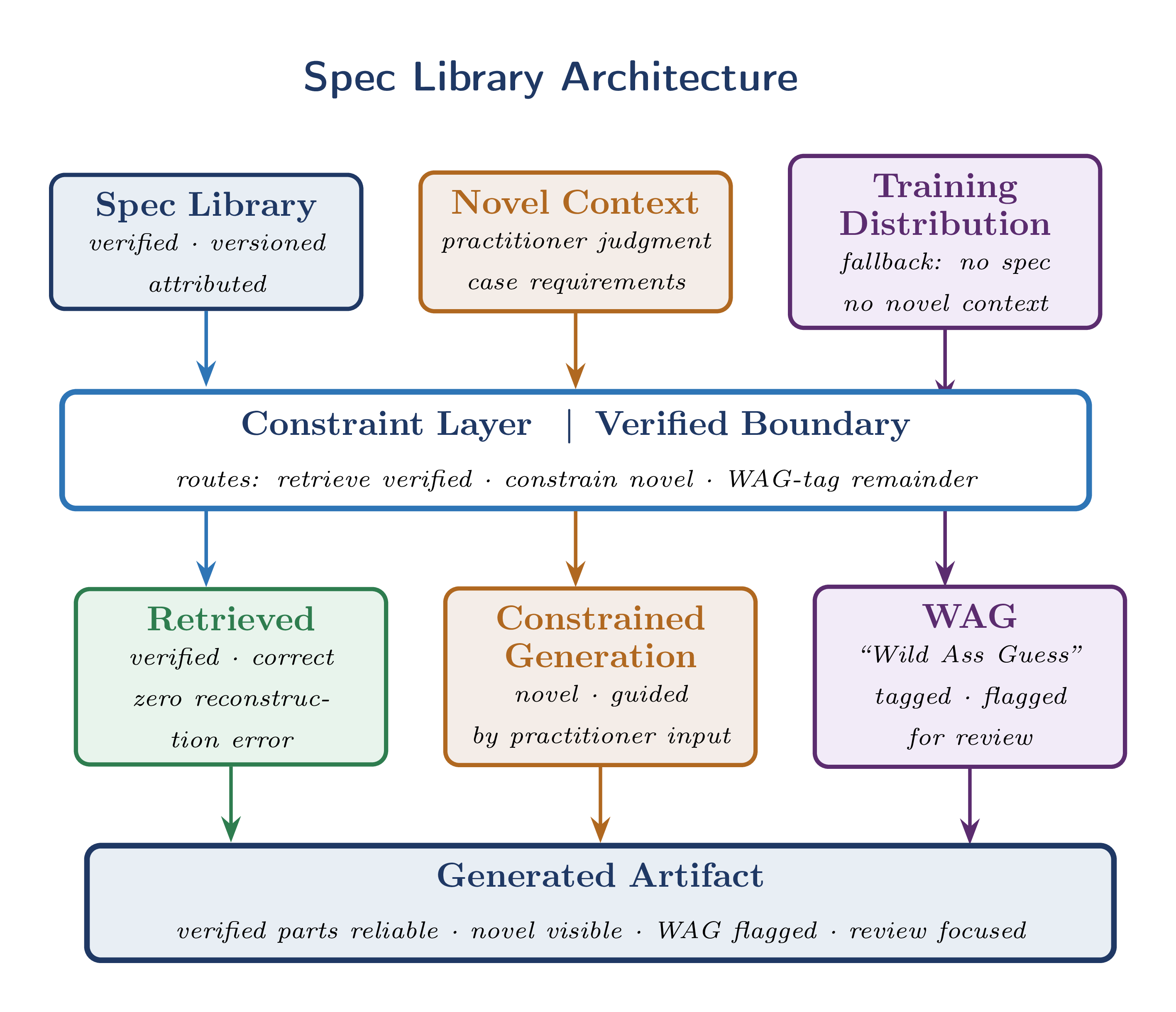
Figure 1b. Spec library architecture. Three sources feed a constraint layer that routes each component to the appropriate generation path.
The pattern in Figures 1a and 1b holds across every domain where LLMs are asked to generate professional artifacts. Each artifact combines two kinds of material: verified components and the results of novel inference. A sorting algorithm implementation relies on known algorithmic methods; a legal contract relies on established clause language; a clinical protocol relies on accepted dosing guidelines. The novel contribution lies in how these components are applied to a specific situation.
Human practitioners generally know where this boundary lies. They recognize when they are applying established practice and when they are exercising judgment. LLMs do not. When asked to generate an artifact, LLMs reconstruct both parts from their training distribution. The known components — the algorithm, the legal clause, the dosing protocol — are reconstructed probabilistically from examples seen during training, rather than retrieved as verified components. (This has a well-known technical term: WAG, or “Wild Ass Guess.”4) That reconstruction is where many silent and sometimes deadly errors originate. The pattern is the same across domains: the boundary between the library’s contents and WAGs is invisible to the automated generator. Making it explicit eliminates a large and consequential class of silent errors — not every LLM failure, but a class large enough to matter enormously in professional practice.
This architecture appeared in Essay 15 as a solution to AI-assisted software development failures. The same architecture applies whenever an LLM is asked to generate consequential artifacts from established knowledge in any domain built on stable, reusable components. That covers most professional fields.
One further point before we proceed: private libraries are part of this ecosystem from the start. A law firm’s proprietary clause library is not in tension with the spec library concept. It is the organizational layer of a hierarchy running from public foundational knowledge through standards bodies through organizational policy to individual practice. The framework accommodates private knowledge. It does not require contributing it to a commons.
For readers arriving without having first read Essay 1: a spec library is a versioned, human-readable collection of specifications that constrain what an LLM generates — the way a type system constrains what a compiler accepts. When an LLM generates code, a legal clause, or a medical protocol, it fills unspecified gaps with probabilistic inference. The spec library approach makes the boundary between verified components and the results of novel inference explicit, so that the verified parts are retrieved rather than reconstructed, and the novel parts are clearly marked as requiring human review.
II. Vannevar Bush’s Unsolved Problem — and Why It Matters Now
In July 1945, Vannevar Bush published an essay in The Atlantic that has shaped how we think about knowledge and machines ever since.6 His diagnosis was precise: human knowledge had outgrown its organizational infrastructure. The problem was the organizing principle, not the volume: alphabetical and categorical classification was misaligned with how knowledge actually works, which is by associative link. One idea leads to another not because they share a category but because they share an associative relationship. The path between ideas is itself knowledge.
Bush proposed the Memex: a machine for storing, navigating, and sharing a personal library through associative trails. A researcher could follow connections between documents, record the path as a named trail, and share that trail with colleagues. The trail itself — the record of which associative links were productive — would become an intellectual contribution. Bush imagined that building such trails would become the primary scholarly contribution: synthesis of existing ones into navigable, shareable paths rather than discovery of new facts.
Why does this matter now? Because the problem Bush diagnosed has compounded. Knowledge is no longer merely hard to navigate; it is being consumed directly by machines that generate new artifacts from it. The organizational failure Bush identified now has a second consequence he could not have anticipated: machines filling the gaps in unorganized knowledge with probabilistic inference (WAGs), invisibly, at scale.
The partial realizations of Bush’s vision each solved part of the problem. Ted Nelson’s hypertext formalized the associative link as the hyperlink. Tim Berners-Lee’s World Wide Web deployed it at global scale. The W3C’s Annotations specification added a layer for attaching meaning and commentary to those links — a closer approximation of Bush’s trails, though still underused in practice. The Semantic Web project attempted full machine-readable semantics through formal ontology languages (RDF and OWL), but their overhead proved too high for mainstream adoption.
What all of these preserved was the link. What none delivered at scale was Bush’s annotation: an associative link that carries meaning, epistemic status, provenance, and verification.7 A hyperlink tells you a connection exists. It does not tell you what the connection means, how reliable it is, who established it, or when it was last checked.
There is a distinction worth naming. Bush’s Memex was a knowledge navigation tool, helping human researchers find and connect existing material. The spec library is a generation constraint, helping machines produce new material reliably from what has been verified. These are related but not identical. The spec library extends Bush’s associative trail to an active consumer he could not have anticipated: a system that does not merely traverse the knowledge graph but generates new nodes in it, constrained by what has already been established.
The formal methods tradition in computer science has argued for decades that separating specification from implementation is the precondition for reliable construction — from Hoare logic and Design by Contract to TLA+ and OpenAPI schemas. These are powerful but demanding tools; most practitioners never use them. The spec library pursues the same architectural principle with a far lower barrier to entry: natural language specifications and structured metadata rather than formal logic or proof systems. The target of construction has changed; the architectural insight has not.
What the Semantic Web failed to deliver at scale, the spec library achieves through pragmatic design: natural language specifications with structured metadata, versioned and attributed, machine-consumable without requiring formal logic. Bush’s associative trails, made semantic, versioned, verified, and connected to the generation process. The dependency relationship between specs carries meaning, not just adjacency. The verification carries epistemic status. The provenance carries authorship and history.
III. The Pattern Across Domains
Practitioners across every consequential professional domain already compose artifacts from verified fragments rather than generating from scratch. This is not new. What is new is that LLMs are now being asked to perform the same generation tasks — without access to the kind of verified-component infrastructure that many professions have worked hard to develop, and without the update propagation mechanisms that keep that infrastructure current. Most professionals in these fields already work this way. A spec library simply extends the scope — from the firm to the ecosystem — and adds the update propagation layer that local implementations cannot provide. Crucially, alerting becomes easier as scope increases: a firm-level clause library can notify its own lawyers; an ecosystem-level spec library can notify everyone who has deployed that clause, everywhere.
Five domains follow, each anchored in documented failures rather than hypotheticals. The pattern of failure is the same in each: verified components reconstructed probabilistically, with no mechanism to flag when the reconstruction is outdated or wrong.
Legal — from documented failures to the solution
The documented failures are already extensive. The well-known confabulation problem — LLMs inventing or hallucinating case citations — is now extensively documented: over 900 documented cases worldwide by early 2026 — approximately 90% from 2025, at a rate that grew from a handful per week before spring 2025 to several per day by year end.8 But confabulation is not the subtler or more dangerous failure. More concerning are the cases of substantive misstatement: LLMs misrepresenting the holdings of real cases, generating legal standards that are plausible but wrong.9 An invented case is at least detectable — a citation that leads nowhere. The misrepresentation of a real case is harder to catch, and harder to explain when it reaches a judge.
The testamentary capacity scenario from Section I is an instance of a third failure mode, distinct from both: correct law from the wrong time. The LLM generates language that was legally sound when most of its training data was written, but has since been superseded. No citation is invented. No holding is misrepresented. The clause simply reflects an earlier state of the law, reconstructed with full confidence from a training distribution weighted heavily toward older documents.
Most people believe that contracts are drafted from scratch by lawyers exercising unique judgment. In sophisticated practice, this is largely not the case.10 Contracts are assembled from clause libraries — standardized, tested fragments that have accumulated meaning through use, interpretation, and precedent. A lawyer deploying a verified clause is not just recycling boilerplate — they are deploying interpretive history that freshly drafted language cannot have.11 The boilerplate is good precisely because it has been tested.
The problem is that these libraries exist at the firm level, not the ecosystem level. An LLM asked to draft a will does not consult any firm’s clause library. It reconstructs from training data — which includes decades of document language in varying states of currency, jurisdiction-appropriateness, and drafting quality — without any record of what it chose or why.
Standardization would change this — but even a partially standardized system would be an improvement in one fundamental way: it would provide names. Right now when an LLM generates a will, there is no way to say “this clause came from X” because there is no X — only a probabilistic reconstruction with no identity and no provenance. One of the oldest insights in philosophy of language applies here: you cannot discuss, critique, update, or be alerted about what you cannot name. A spec library gives components identities. Those identities enable everything else: the journal article analyzing v2.37, the alert when v4.2 is superseded, the record of which documents used which version. Naming is the first gift of standardization; verification is what you build on top of it.
Imagine a law journal article titled “Testamentary Capacity Clause v2.37: Consequences and Inadequacies.” Fifty pages of dense analysis. Proposed modifications for cognitive impairment cases, foreign nationals, blended families. This article is possible only because there is a v2.37 for everyone to analyze together. Standardization does not flatten the intellectual landscape. It maps it, which is the precondition for exploring it productively. A will drafted using verified language for testamentary capacity and execution requirements need not be a standard will. The verified components handle the routine questions correctly, freeing the drafter’s full attention for the genuinely circumstance-specific ones.
Medical — documented failure even in a professional system
The medical domain is the most striking example because the failure is documented in a professional, standardized-component system, not in consumer AI use. A 2025 peer-reviewed study examined Electronic Health Record (EHR) order sets for alcohol withdrawal syndrome across multiple hospital organizations.12 Order sets are exactly the verified-component model applied to clinical care: standardized collections of treatments, medications, and protocols assembled by clinical experts and embedded in EHR systems for point-of-care use. They are professionally composed from approved components, not vibe-written.
The study found that a widely-shared templated order set — used across multiple hospital organizations — was still based on 2004 American Society of Addiction Medicine (ASAM) guidelines, despite substantially revised 2020 guidelines having been available for five years. The time lag was not caused by carelessness or incompetence. It was caused by the absence of an update propagation mechanism. No one was automatically notified that the template they were using was misaligned with current guidelines. The component was verified at the time of creation. It had not been re-verified since.
When a clinician asks an LLM to confirm a dosing protocol or summarize current guidelines, the LLM reconstructs a WAG from its training distribution rather than retrieving a verified current guideline.13 An outdated dosing protocol reconstructed with high confidence is more dangerous than an uncertain one, because it does not signal the need for verification. The EHR order set study shows that the update propagation problem exists even when practitioners are using standardized components — which makes it more urgent, not less. The alert mechanism is not just a feature for consumer AI use. It is a feature every professional system needs.
Education — verified components without verified currency
Teachers already compose lesson plans from verified components: standards-aligned learning objectives, pedagogical frameworks, pre-built activity blocks. Teachers Pay Teachers (TPT), the largest marketplace for K-12 educational resources, hosts over three million materials with more than a billion downloads — a mature ecosystem of shared, reusable teaching components.14
The structural gap is familiar. A 2022 study of over 500,000 TPT resources found that Common Core alignment, while claimed by many resources, was not a focal point of most content — meaning the verified-component layer is nominal rather than rigorous. When a state revises its curriculum standards, there is no systematic mechanism to notify teachers whose lesson plans reference the old version. Verified components exist. The update propagation layer does not.
Scientific Papers — where citation infrastructure already exists
Scientific papers already have a mature citation infrastructure. When a paper says “following the method of Smith et al. 2019,” it is gesturing at a verified fragment. The spec library extends that infrastructure to make method references machine-consumable, versioned, and checkable against the current version. The novel contribution of a paper is precisely the residual after all standard methods are tagged.15
Engineering Calculations — where regulatory liability follows the certifier
Structural engineering reports, thermal load studies, and environmental assessments all reference approved standards. Building codes already specify which calculation methods are permitted — a constraint spec system operating informally, without the infrastructure to connect it to generation workflows.16 An LLM generating a thermal load calculation that silently uses a method superseded by an updated energy code produces a document that looks authoritative but is professionally defective. The liability follows the professional who certified it, not the LLM that generated it.17
The pattern across all five domains — legal, medical, education, scientific, engineering — is identical. Practitioners already compose verified fragments rather than generating from scratch. The spec library is not proposing something new. It is proposing the infrastructure that connects this universal practice to LLM generation workflows, plus the update propagation layer that none of the existing tools provide.
These failures have costs: in legal sanctions, in vacated court orders, in compromised patient care. Standard language is part of the infrastructure that prevents them.
IV. Standard Language Is Not the Enemy of Good Language
A predictable objection: if all wills use the same verified testamentary capacity clause for common needs, if all NDAs use the same verified non-compete language for common circumstances, do we lose the diversity from which better practice emerges? The evolutionary analogy presents itself — monocultures are fragile, genetic diversity is the raw material of adaptation.
The objection is worth taking seriously. The response has three parts.
First: standardization redirects scrutiny rather than reducing it. When everyone uses the same verified clause for common needs, collective professional attention concentrates on whether that clause is correct and sufficient. The verified text becomes a focal point for improvement. When a court interprets it unexpectedly, the entire community learns simultaneously. The law journal article analyzing testamentary capacity clause v2.37 is possible only because there is a v2.37 to analyze. That is more evolutionary pressure on the standard language, not less.
Second: the spec library standardizes components, not artifacts. A will using verified language for testamentary capacity and execution requirements need not be a standard will — the routine parts are correct and the specific circumstances of the testator shape everything else. The drafter’s full attention is available for the genuinely circumstance-specific questions because the approved components have already answered the routine ones. Standardization amplifies the novel contribution by handling the routine, not by suppressing it.
Third, and most important: the alternative to standard language is not creatively diverse language. If created by an undisciplined LLM, it is random language. This is where the evolutionary analogy cuts the opposite direction from what the objection implies.
Evolutionary diversity is variation under selection pressure. Current LLM generation without spec constraints is genetic drift, not directed evolution.
The spec library introduces selection pressure: only verified, tested components enter the library. The result is directed evolution: the novel contributions are the variation, the library is the selected gene pool. Novelty detection — identifying which untagged patterns keep appearing independently across artifacts — is the mechanism that incorporates successful variations into the library over time.
Evolution is expensive selection. Most mutations are insignificant or damaging. A defective contract clause can destroy a business. A wrong dosing specification can kill a patient. The approved baseline is not a constraint on human judgment — it is the precondition that makes human judgment effective.
The monoculture fragility argument deserves a precise answer. The adaptive immune system offers a better analogy. Its power comes not from uniformity but from a mechanism for learning: the thymus teaches T-cells to distinguish self from non-self before they are deployed, and the system updates its trained responses when new pathogens appear. The spec library works the same way. The verified components are the trained baseline. The update and revocation mechanism is the adaptive response — when a new legal interpretation or a security finding appears, the spec is updated, and every registered user is notified.18 An agricultural monoculture has no such adaptive mechanism. A spec library ecosystem does.
V. Higher Quality at Lower Cost
Using spec libraries can lead to higher quality output at lower cost — directly addressing the urgent need to reduce LLM energy consumption and compute expenditure. That may seem like an odd claim. Let me explain.
When a developer asks an LLM to implement string search, the model does not retrieve a verified sorting algorithm implementation. It samples from a probability distribution shaped by every string search implementation in its training data — correct ones, subtly wrong ones, outdated ones, ones appropriate for different contexts — and produces a WAG that merely resembles a known artifact. The output looks like a string search implementation. Whether it is a correct one is a separate question.
The same thing happens when a lawyer asks an LLM to draft a non-compete clause, or a researcher asks it to describe a spectroscopic method, or a clinician asks it to confirm a dosing protocol. The model reconstructs from its training distribution, producing something that resembles the target well enough to pass a quick review. The subtle errors — the outdated assumption, the jurisdiction-specific exception omitted, the edge case not handled — are invisible precisely because the output looks so plausible.
This reconstruction is expensive in two ways simultaneously. First, compute: the model evaluates probability distributions over a vast space of possible outputs to produce something that merely resembles a known artifact. Second, quality: the result inherits whatever errors were present in the training distribution, with no mechanism for selecting the correct variant over the merely plausible one.
Probabilistic reconstruction of what is already known is the hidden waste in every unconstrained LLM generation. It is expensive and unreliable simultaneously. Use of a spec library eliminates it.
With a spec library, the known components are retrieved rather than reconstructed. The sorting algorithm implementation, the non-compete clause, the spectroscopic method, the dosing protocol — each arrives as a known-correct artifact with explicit provenance. The error modes introduced by unconstrained generation — silent omissions, outdated variants, jurisdiction-inappropriate choices — are eliminated for the retrieved portions. The residual error rate applies only to the novel contributions, which is where human review should be concentrated anyway.
This has a direct consequence for the cost of human oversight. Current practice requires reviewing the entire output of an unconstrained LLM, because any part of it might be wrong — the verified components reconstructed with errors, the novel inference applied incorrectly, and everything in between. Use of a spec library makes the boundary explicit. The verified portions arrive with provenance; a reviewer can confirm that the correct spec was retrieved without re-deriving it from first principles. The WAG portions are explicitly flagged as such, so the reviewer knows precisely where circumstance-specific judgment is required and where it is not. Human attention is then available in full for the genuinely novel parts — the circumstance-specific judgment that no library can supply and no reviewer should skip. This is a concentration of oversight where it creates value, not a reduction in it.
The compute cost falls for a related reason, though not primarily through token-level effects. The primary cost of LLM generation is repeated probabilistic reconstruction and the rework it induces — retries, corrections, extended review cycles — not token selection. In practice, LLM workflows follow a generate-review-find-issue-regenerate loop that is extremely expensive. Spec libraries change that structure: retrieve known components, generate only novel parts, review only novel parts. Cost reduction comes from eliminating reconstruction of what is already known, compressing prompts, and shifting computation from repeated online inference to amortized offline validation.
This economic structure has been demonstrated at scale in search.19 A predictive caching architecture showed that precomputing results against anticipated demand produces both lower latency and higher quality simultaneously. A cache of roughly 20 million precomputed results represented a substantial fraction of daily query volume and saved several hundred thousand processor cores. The spec library applies the same inversion to LLM generation: the library’s contents precomputed by domain experts, retrieved at generation time, novel computation concentrated on what actually requires it.
The result: higher quality at lower cost. The combination runs against the standard tradeoff in computing: higher quality costs more. Use of a spec library inverts it by replacing reconstruction with retrieval — a structural improvement, not a capability improvement.
Much of what looks like a model capability problem is actually an architecture problem. The model is not failing because it lacks capability. It is failing because it is being asked to do expensive probabilistic reconstruction of things that should be retrieved. Better models will not fully solve that problem. Better architecture will.
VI. The Simple Structure Underneath
The image below was produced by applying a set of eight rules first studied by Stephen Wolfram.20 The starting condition: a single black cell, everything else white. The rules specify, for each cell, whether its next state should be black or white based on its own state and the state of its two immediate neighbors. That is all. Nothing more.
The complexity in the output is real. The pattern never repeats, and its statistical properties are indistinguishable from random noise. But the complexity lives in the output, not in the rule. The rule is trivial. Identifying the rule dissolves the apparent mystery without eliminating the complexity.

Rule 30 (Wolfram, 1983): eight simple rules, one black cell, 300 generations. Wolfram used this output as a pseudorandom number generator in Mathematica.
The failure modes surveyed in Section III look more complex than they are. Rule 30 suggests why: surface complexity can conceal a simple underlying mechanism. The reliability problem in LLM generation has the same structure. Across domains — software, legal drafting, scientific methods, medical protocols, engineering calculations, education — the failure modes look diverse and domain-specific. They reduce to a single mechanism: the boundary between the library’s contents and WAGs is invisible to the automated generator, and making it visible is the remedy. That reduction covers a large and important class of silent errors — a class that is both large and consequential, though not every LLM failure.
The KISS principle demands honesty about what is and is not simplified. What the spec library genuinely simplifies: the mechanism of the reliability problem. One structural observation covers the class of errors described above.
What remains genuinely complex: the governance problem — who verifies or certifies, who resolves disputes, how standards evolve — is not simple. The incentive problem is not simple either: unlike open source code, which maintainers need for their own work, spec libraries are closer to public goods and may require stronger institutional structures to sustain. The authoring cost — writing good specs is expensive and most organizations struggle to maintain documentation — is not simple. The semantic drift problem — natural language specs can change meaning without changing bytes, as when a court reinterprets “good faith” — is not simple. The version proliferation problem — spec ecosystems tend to accumulate versions that are never retired — is not simple. The fragmentation problem — legal standards vary by jurisdiction, medical guidelines by country, educational standards by state — means that federated governance structures, not a single universal authority, are likely the realistic path.
The more careful claim: use of a spec library simplifies the right thing — it operates at the correct level of abstraction at which the problem has a tractable structure. The remaining complexity is visible and addressable rather than hidden and compounding.
VII. The Infrastructure We Should Build
Bush ended “As We May Think” hoping that we could find a way to organize the record of human knowledge, making it accessible and usable rather than buried and lost. Eighty years later the problem is not accessibility. Every professional in every domain has more relevant literature than they can possibly read. The problem is that the record is not organized in a form that the machines now doing much of the reading and writing can use reliably.
In the pre-LLM world, knowledge systems helped humans find information. In the LLM world, knowledge systems must help machines compose artifacts safely. That shift in function is the reason the spec library is needed now in a way it was not before. The Memex was a navigation tool. The spec library is a generation constraint. Both address the same underlying problem: the organization of human knowledge, but at different moments in the relationship between knowledge and the machines that process it.
The spec library could be that organizational infrastructure. Not just for software. Not just for law. Not just for medicine. For every domain where knowledge is composed into consequential artifacts and where getting it wrong has consequences that matter.
An alert system is a natural extension of the same infrastructure. As specs are updated — a security finding, a Supreme Court interpretation, an updated clinical guideline — every registered user of the affected version could receive notification.21 An LLM with memory of the specs it has previously used could go further: scanning prior work to flag documents that drew on a now-superseded version, or identifying WAGs in existing documents that could be replaced by verified components added to the library since the document was drafted. This is only possible if the language is standardized and the usage is recorded. The SCOTUS scenario that opened this essay is not a fantasy. It is the direct consequence of taking the spec library seriously.
The bootstrap starts with what already exists: law firms maintain private clause libraries, medical systems have order sets, schools use standards-aligned lesson components. The spec library framework does not require these to be replaced — it requires them to be connected to a shared versioning and update infrastructure. The private library is the organizational layer. The public spec is the foundational layer above which private variation operates.
A further bootstrapping mechanism is available that existing tools like Henchman approximate but do not fully exploit. An LLM processing documents at inference time — reviewing contracts, analyzing briefs, summarizing clinical notes — sees patterns across millions of documents from different firms, jurisdictions, and practice areas simultaneously. It can identify which fragments appear repeatedly and consistently across contexts: the candidates for verified spec entries. The feedback loop is self-reinforcing: the LLM identifies candidates from what it processes, human experts verify them, verified entries enter the spec library, and the next round of novel contributions becomes the next round of candidates. Human experts do not start from a blank page. They start from LLM-identified patterns in real professional practice. The benefit is not confined to individual users. Each verification adds to a shared library of ever-increasing utility — a public good whose value grows with every contribution and every use.
The cryptographic layer that would make conformance claims machine-verifiable: W3C Verifiable Credentials, Decentralized Identifiers, signed provenance records in code and documents — exists and is ready to be applied.22 That application will be developed in a subsequent essay. The point here is simpler: the spec library’s value does not depend on cryptographic verification. It begins with versioned, human-readable, attributed specifications. The first verified entry for a testamentary capacity clause, a standard spectroscopic analysis method, or a GDPR-compliant data handling protocol could be written today by a domain expert with an afternoon and a text editor.
Bush’s trails are waiting to be built. The machines are waiting to follow them. The knowledge exists. The infrastructure does not. Yet.
Footnotes
“Vibe coding” was coined by Andrej Karpathy in February 2025 to describe directing AI systems to write code through natural language prompts without detailed specification of the desired behavior. “Vibe-writing” is not universally welcomed; see Sirsh. “Vibe Writing Shouldn’t Be a Thing.” Drafter, Substack, April 2025 (https://drafts4life.substack.com/p/vibe-writing-shouldnt-be-a-thing), which argues that the value of writing lies in transparency of process and maintained human agency — a concern fully compatible with the spec library’s provenance and WAG-tagging mechanisms.↩︎
Clause library software for legal professionals has matured into a substantial commercial category. Leading tools include ClauseBase (now acquired by LawVu; clausebase.com), which allows lawyers to build, version, and track clause libraries across their entire document portfolio; Henchman (now Lexis Create+), which “creates a database from a firm’s past contracts” and surfaces pre-approved clauses at drafting time — the private library layer the spec library describes; Draftwise, which uses historical firm deal data to guide drafting; and Spellbook, which benchmarks clauses against market-standard terms. Enterprise clients include CMS, Deloitte Legal, AES, and Axel Springer. All of these tools solve the within-firm consistency and retrieval problem well. None address cross-firm post-generation update propagation — the alert mechanism that is the spec library’s contribution above the existing infrastructure.↩︎
Ackoff, Russell L., Martin C. J. Elton, Thomas A. Cowan, James C. Emery, Peter Davis, Marybeth L. Meditz, and Wladimer M. Sachs. The SCATT Report: Designing a National Scientific and Technological Communication System. University of Pennsylvania Press, 1976. Chapter 1, pp. 6–7. Ackoff’s two constraints for idealized design are stated in italics in the original. The characterization of idealized design as “not a work of science fiction” appears on p. 7. SCATT stands for Scientific Communication and Technology Transfer. The project was funded by the National Science Foundation’s Office of Science Information Service.↩︎
WAG: “Wild Ass Guess” — an estimate of lesser worth than a SWAG (Scientific Wild-Ass Guess). The term originated in US military usage and is applied to any rough estimate made without rigorous calculation or verified grounding. Wikipedia: https://en.wikipedia.org/wiki/Scientific_wild-ass_guess↩︎
Wyman, Bob. “The Next Turn of the Spiral: Fixing Vibe Coding Without Reinventing Software Engineering.” Substack, March 2026. https://mystack.wyman.us/p/the-next-turn-of-the-spiral-fixing. That essay acknowledged prior art explicitly: Design by Contract (Meyer), TLA+ (Lamport), Alloy, SyGuS, OpenAPI, and W3C conformance testing. The spec library concept is not a replacement for these traditions but an architectural layer connecting them to the LLM generation workflow.↩︎
Bush, Vannevar. “As We May Think.” The Atlantic, July 1945. https://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/↩︎
W3C Web Annotation Data Model. W3C Recommendation, 23 February 2017. https://www.w3.org/TR/annotation-model/. The W3C Annotations specification provides a standard for attaching structured commentary, provenance, and meaning to web resources — the closest existing infrastructure to Bush’s associative trails with epistemic status. Its limited mainstream adoption is itself evidence of the gap the spec library addresses.↩︎
Mata v. Avianca, Inc., 678 F. Supp. 3d 443 (S.D.N.Y. 2023), is the landmark case: lawyers submitted a brief containing six completely fabricated cases generated by ChatGPT. Since then the phenomenon has grown dramatically. Researcher Damien Charlotin (HEC Paris / Sciences Po) maintains a public database of legal decisions worldwide involving AI-generated hallucinated content in court filings. As of March 2026, the database documents over 900 such cases across 31 countries, with approximately 90% issued in 2025. Charlotin reported the rate escalated from approximately two cases per week before spring 2025 to two or three per day by September 2025, and five or six per day by December 2025. Database: damiencharlotin.com/hallucinations. A Stanford RegLab study found hallucination rates of 33% for Westlaw AI-Assisted Research and 17% for LexisNexis Lexis+ AI on legal queries. See Magesh et al., “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools,” Journal of Empirical Legal Studies (2025); arXiv:2405.20362.↩︎
Two documented failure modes beyond outright fabrication. (1) FABRICATED CITATIONS: Johnson v. Dunn, No. 2:21-CV-01701-AMM (N.D. Ala. July 23, 2025): ChatGPT-generated citations in briefs submitted by attorneys at a prominent national law firm; three attorneys sanctioned, publicly reprimanded, disqualified from the case, and referred to the Alabama State Bar. Shahid v. Esaam, Georgia Court of Appeals, June 30, 2025 (not Florida as sometimes misreported): a pro se litigant’s brief contained 15 citations of which 11 were hallucinated; one supported a claim for attorneys’ fees; the trial court issued an order partially relying on the hallucinated holding; on appeal the court vacated the order and remanded. (2) MISREPRESENTATION OF REAL CASES: Fivehouse v. U.S. Department of Defense, No. 2:25-cv-00041 (E.D.N.C. 2025–2026): the court’s own order identified fabricated quotes and misstatements of the holdings of multiple real circuit court opinions — cases that existed but whose holdings were described in ways the court found inaccurate; the assistant US attorney responsible was fired. The New York Appellate Division noted the same failure mode in Deutsche Bank Nat’l Trust Co. v. LeTennier, 2026 NY Slip Op 00040 (3d Dep’t Jan. 8, 2026), observing that even where AI provides accurate case citations it may misrepresent the holdings of those cases, often in a direction favorable to the party supplying the query. The currency/jurisdiction mismatch problem — correct law for the wrong time or place — is a structural variant of failure mode 2 and is illustrated by the testamentary capacity scenario in Section I; it is less documented in sanctions decisions because it is harder for courts to detect.↩︎
That legal drafting already operates largely through assembly of standardized fragments is underappreciated outside the profession. See Adams, Kenneth A. A Manual of Style for Contract Drafting. 4th ed. American Bar Association, 2017.↩︎
The ISDA Master Agreement and its definitional booklets represent the most mature domain-specific verified fragment library in commercial practice. A direct ancestor of the “verified clause” concept is Ian Grigg’s Ricardian Contract (1990s), in which a document is simultaneously a legal agreement and a machine-readable parameter set. See Grigg, Ian. “The Ricardian Contract.” First IEEE International Workshop on Electronic Contracting, 2004.↩︎
Electronic health record order sets represent verified-component composition in clinical practice. A 2025 study of hospital EHR order sets for alcohol withdrawal syndrome found that a widely-shared templated order set was still based on 2004 American Society of Addiction Medicine (ASAM) guidelines rather than the substantially revised 2020 guidelines — illustrating the time lag associated with implementing new guidance even in a professional system with standardized components. The study noted that “the wide reach of a single templated order set suggests an opportunity to broadly shift adoption of guidelines” — precisely the alert mechanism argument. See: Crotty et al. “Guideline concordance of electronic health record order sets for hospital-based treatment of alcohol withdrawal syndrome.” Journal of General Internal Medicine, 2025. PMC12276874.↩︎
FDA DailyMed provides structured drug labeling data; SNOMED CT provides a versioned clinical terminology standard; ICH guidelines govern pharmaceutical regulatory submissions. None are currently connected to LLM generation workflows in any systematic way.↩︎
A study analyzing over 500,000 resources on Teachers Pay Teachers found that Common Core standards, while present, were “not a focal point of most content” — meaning the marketplace is large but the verified-component layer is thin and inconsistently applied. See: Rosenberg, J.M. et al. “Analyzing 500,000 TeachersPayTeachers.com Lesson Descriptions Shows Focus on K-5 and Lack of Common Core Alignment.” Teaching and Teacher Education, 2022.↩︎
Scientific reproducibility problems arise from multiple sources: data availability, undocumented experimental conditions, statistical misuse, and code differences. Method tagging addresses the specification gap specifically and does not claim to solve the broader reproducibility problem. See Baker, Monya. “1,500 scientists lift the lid on reproducibility.” Nature 533, 452–454 (2016).↩︎
Engineering standards bodies whose specifications constitute proto-spec library entries include AISC (steel construction), Eurocode (European structural standards), ASCE, ASHRAE (mechanical/energy), and ISO. None are currently connected to LLM generation workflows in any systematic way.↩︎
Additional domains: insurance policy language (ISO clause forms), patent applications, actuarial reports (Actuarial Standards of Practice), pharmaceutical regulatory submissions (ICH Common Technical Document), international trade documentation (UCP 600, Incoterms), and academic curriculum accreditation materials.↩︎
The alert system requires no new infrastructure beyond what the spec library already provides. The CVE (Common Vulnerabilities and Exposures) system maintained by MITRE Corporation demonstrates the model: vulnerability discoveries come from distributed contributors, MITRE maintains the registry, the process is transparent, and no single authority is the source of trust. Who bears responsibility if a verified spec is wrong is a governance question addressed in a forthcoming essay.↩︎
Wyman, Robert M., Trevor Strohman, Paul Haahr, Laramie Leavitt, and John Sarapata. “Predictive Searching and Associated Cache Management.” US Patent Application US20100318538A1. Filed June 12, 2009. Assigned to Google LLC. The system precomputes search results against anticipated queries during idle time, achieving lower latency and higher result quality simultaneously by shifting computation away from the moment of user demand — the same economic structure the spec library proposes for LLM generation.↩︎
Rule 30 is one of 256 elementary cellular automaton rules identified and studied by Stephen Wolfram. See Wolfram, Stephen. A New Kind of Science. Wolfram Media, 2002. The image was generated independently using Python’s standard library; no Wolfram code or proprietary material was reproduced. Rule 110, similarly trivial, has been proven Turing complete. See Cook, Matthew. “Universality in Elementary Cellular Automata.” Complex Systems 15, no. 1 (2004): 1–40.↩︎
See note 17 above.↩︎
The W3C Verifiable Credentials specification and Decentralized Identifiers (DID) provide cryptographic infrastructure for making conformance claims machine-verifiable rather than merely human-readable. The application to spec library verification — including novel questions about LLMs as credential subjects and credential chaining for compositional specs — will be developed in a subsequent essay. Note that the original W3C working group was named the “Verifiable Claims Working Group,” a name that more accurately captures the epistemic structure: a spec library entry is a verified claim, not a credential in the identity-management sense.↩︎